
What is a Customer Context Layer? Six Key Principles
TL;DR
- The bottleneck in agentic AI has shifted. Model capability used to be the constraint. Grounding is the constraint now. An AI agent is only as good as the context it reasons over.
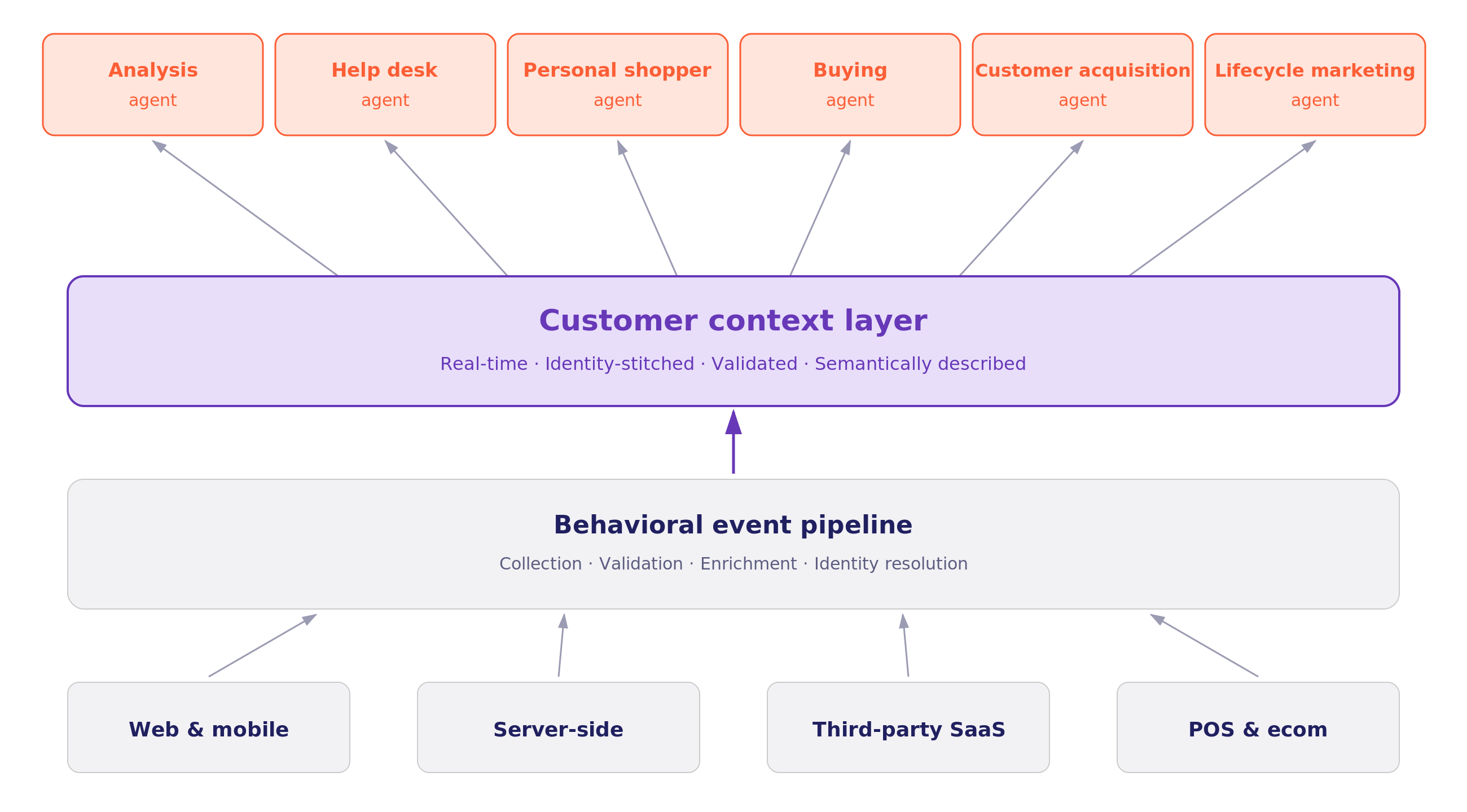
- A customer context layer is the infrastructure that gives AI agents real-time, identity-resolved behavioral context about each customer or user. It sits alongside your enterprise data layer (Snowflake, Databricks, BigQuery), feeding context to customer-facing agents in real time and analytics agents through the warehouse, all from one source of truth.
- 57% of organizations surveyed by LangChain in late 2025 already have AI agents in production. More than 90% of companies, per Gartner, don't have the data foundation those agents need.
- Six principles define what a customer context layer has to embody: shift left on data quality and governance, complete behavioral coverage including agents acting on the customer's behalf, real-time information-dense context, owned by your team and composable by design, a flywheel of compounding intelligence, and deployment in days rather than quarters.
- Consumer expectations of AI are rising fast. The businesses keeping pace are the ones with the customer context layer to match.
The bottleneck has moved
A year ago, data and AI leaders kept asking whether the model could do the job. Today, the model is usually good enough. What stops an AI agent from being trustworthy is the poor quality of the context it reasons over.
So the bottleneck has moved. From model capability to grounding.
When LangChain surveyed 1,340 agent engineers in late 2025, 57% of respondents had agents in production. They also received write-in responses from large enterprises who expressed ongoing difficulties with context engineering and managing context at scale.
Thomas Kurian at Google Cloud put it plainly in his Gemini Enterprise launch post: "an agent is only as good as its context." Gartner reckons that more than 90% of companies don't have an AI-ready data foundation. Half of CDOs say data quality is their biggest challenge.
It's clear that the agentic build cycle is here. The issue, though, is the shaky customer data foundation underneath it, which is what most companies still haven’t properly solved.
That's the gap a customer context layer fills.
Two flavors of agentic AI, one foundation
There are two kinds of agents that are now in production. And they each need different things from their data infrastructure.
- Analytics agents like Snowflake Intelligence, Databricks AI/BI Genie, and Cortex Analyst sit on top of the data platform. They answer questions about what's already in the warehouse, for internal users. The semantic infrastructure built around modern data platforms covers most of what they need.
- Customer-facing agents present a more challenging problem to solve. They're talking to your customer and users in real time. The context they need has to be fresh, identity-resolved, and complete enough for the agent to act on the customer's behalf without getting it wrong.
This piece focuses on the customer-facing agent problem. But it’s important to note that the same behavioral data foundation that grounds customer-facing agents also lands richer customer data in your warehouse, which makes your analytics agents better too. So you have one data foundation, and two consumption modes.
What is a customer context layer?
A customer context layer is the infrastructure between your data platform and your customer-facing AI applications. It collects behavioral events from every surface a customer touches, resolves their identity in real time, and delivers structured context to AI agents in a form they can reason over. The same data lands in your warehouse, where analytics agents can pick it up downstream.
A customer context layer sits alongside your enterprise data layer rather than beneath it. The enterprise data layer was built for analysts and ML pipelines reasoning over query-resident data. A customer context layer has a different job. It feeds the customer-facing agent the answers to "who is this customer, what are they doing right now, and what does that mean" in real time, in the live session.
The conversation about this layer is already happening. In his March 2026 research report with Databricks, Scott Brinker describes customer data infrastructure evolving from "systems of record" into "systems of context." Andrej Karpathy and Tobi Lütke have spent 2025 making the case that context engineering is the discipline that replaces prompt engineering for production agents. A customer context layer is the productized form of that discipline, applied to customer-facing AI.
How a customer context layer differs from a semantic layer, a CDP, and a feature store
People ask me whether we've just renamed a category. We haven't. Here's how a customer context layer differs from each of the things people tend to confuse it with.
A semantic layer describes what the data in your warehouse means. It tells an analytics agent what "conversion" means, how "active user" is calculated, where "qualified lead" comes from. A customer context layer feeds the semantic layer the real-time behavioral signal those definitions point at. The two work together.
A CDP collects customer records (who someone is) and pushes them to marketing engagement tools like email service providers, ad platforms, and website experiences. It’s more narrowly focused on marketing activation, whereas a customer context layer underpins your entire customer-facing digital estate. It collects behavioral context (what someone is doing across your digital estate right now) and serves it to your ML models and customer-facing agents in real time, as well as to analytics agents through the warehouse.
A feature store serves pre-computed features to machine learning models on a scheduled cadence. A customer context layer serves real-time, identity-resolved behavioral context to ML models and AI agents that need to act in the current session. The two complement each other.
Why customer context is the hardest context layer to build
Most context layers can be built directly on top of a warehouse. Customer context is the difficult exception, because the customer is a moving target. A handful of constraints hit at once, and each one matters because of what it costs the customer-facing agent if you skip it.
Timing. Your customer has a finite amount of attention to give in any day, and dozens of things are competing for it. When they're engaging with your digital estate right now, you have a small window to understand what they're trying to do and respond most effectively. Miss the window and the moment is gone. By the time the data lands in the warehouse on a batch cadence, the customer has already moved on.
Identity matters because the agent can't engage with what it doesn't recognize. If the layer can't tell that this is the same buyer who was researching with you yesterday, or that the agentic browser on your site this morning is acting for the user who logged in last week, the agent has nothing to work from. It treats every interaction as a first encounter, and customers feel it.
Agents acting on the customer's behalf matter because this is a mode of interaction we think will become increasingly important. Customers are turning up accompanied by their own AI agents. A procurement research bot doing due diligence on your product is the same buyer as the CRO who logs in directly the following week. The layer has to recognize human and agent as related actors and instrument both.
Depth and breadth matter because better understanding produces better service. An agent that knows what the customer is trying to do, where they're getting stuck, what they care about, their brand preferences and their price sensitivity is well equipped to help and influence. An agent without that depth is guessing. The richer and broader the picture, the better the agent can serve.
Accuracy matters because the agent acts on whatever the layer just told it. In analytics you can clean the data downstream. In real-time decisioning, you can't. Wrong context becomes a wrong recommendation, a wrong intervention, a wrong tone, served to a real customer in real time.
Composability matters because no single vendor can deliver the full picture. Customer intelligence has to pull from a wide range of sources and feed an equally wide range of agents, some customer-facing and some not. Locking the data into one vendor's environment cuts off both ends. Composability is what keeps the picture complete.
Six principles follow from this list. Each one is the architectural answer to one or more of the constraints above.
Six principles of a customer context layer
1. Shift left on data quality and governance
If you want assurance that the customer context you deliver to an agent is accurate, you need assurance over how the data has been processed from the point of creation through to delivery. Any approach that depends on collecting first, spotting data quality problems later, and fixing them after the fact is too slow for an agent that's already acting on the data in real time.
The customer context layer has to enforce quality and governance at the source. Validate events as they're collected. Reject or flag what doesn't conform before it propagates anywhere. That way the data that reaches the agent has already passed the bar that matters.
The agent is only as good as what it just read. If what it just read was bolted on after the fact and never validated, the agent will confidently get it wrong.
Failure mode. A retailer launches a shopper agent for abandoned carts. Tracking was bolted on after the fact, with no validation layer catching discrepancies at collection. The add-to-cart event fires inconsistently across mobile and web. The agent reminds customers about carts they've already bought, or misses high-intent users entirely. The dashboard looks fine. The damage shows up months later when someone traces a drop in conversion back to the source.
2. Complete behavioral coverage, including the agents acting on the customer's behalf
A customer context layer covers every customer-facing surface. Web, mobile, server-side, in-app. It captures more than clicks. Scrolls, views, hovers, in-session sequences, the proprietary custom events your competitors can't replicate.
The more complete the picture, the better equipped the agent is to help the customer. Coverage matters across two dimensions.
- The first dimension is the surfaces the customer interacts with directly: web, mobile, in-app, server-side, embedded experiences. Each is a behavior stream, and a surface that goes uncaptured leaves the agent with a partial picture.
- The second dimension is the interactions where an AI agent is acting on the customer's behalf: a procurement research bot evaluating your product, a personal AI assistant comparing options, a shopping agent placing an order. This is a mode of customer interaction we think will become increasingly important. A customer context layer that filters this traffic as bot noise discards a real intent signal. One that treats human and agent as unrelated visitors fragments the customer view. The layer has to see them as the same buyer in different forms.
If your coverage is partial, your context is partial. Your AI agents end up working from a misleading picture of who the customer is and what they're trying to do.
Failure mode. A financial services company builds a support agent with CRM data and purchase history, but no in-app behavioral signal. A customer who has spent twenty minutes failing to complete a balance transfer calls in. The agent greets them as if nothing has happened. It has no way of seeing the twenty minutes of struggle that just took place inside the app.
3. Real-time, information-dense context
A customer-facing agent's context window is finite. There's only so much information you can hand it before adding more stops helping. The customer context layer has to distill a deep and broad picture of the customer into something compact and immediately actionable. Agents reason like people. A helpful agent is one that understands what the customer is trying to achieve, recognizes when they're struggling, knows enough about who they are to be attentive to their needs, and is empowered to help. That's what the customer context layer has to surface, in real time, in a form the agent can act on.
Batch-based systems fail on timeliness by design. By the time the data lands in the warehouse, the moment has passed. But speed alone won't get you there. Raw event tables handed to an LLM are noise. Context engineering is the work of turning that noise into something an agent can reason over.
That means translating behavioral data into structured, semantically described representations the agent can actually use. Bad context delivered fast is worse than no context at all.
Failure mode. A travel marketplace deploys a concierge agent on top of a feature store refreshed nightly. A customer who searched for Barcelona flights three times that morning, then abandoned mid-checkout, gets treated by the agent as a cold prospect. The agent opens with a generic welcome offer. The customer disengages. The moment, and the revenue, is gone.
4. Governed by your data platform, composable by your data team
Your customer data is your secret sauce. It's yours uniquely, built from the relationship you've cultivated with each customer over time. If you want to keep cultivating that relationship and keep owning it, you have to own the data and the intelligence built on top of it. That means the customer context layer has to run on your own tech, owned by your own team. Your data team owns the schemas, the models, and the semantic definitions. Your AI teams inherit the outputs.
Schemas flow into dbt models. dbt models flow into semantic definitions. Semantic definitions flow into AI-ready outputs. The customer context layer plugs into your warehouse, whether that's Snowflake, Databricks, or BigQuery, and activates through your existing tooling.
It also has to be composable. Customer intelligence has to pull from the widest possible range of data sources and feed an equally wide range of agents, some customer-facing and some not. No single vendor can deliver that full scope. Composability is how you keep the picture complete. If the customer context layer lives inside a vendor's infrastructure, you've handed over the asset that makes your relationship with the customer durable.
Failure mode. A media company builds its content recommendation engine on a CDP's behavioral data. Two years in, the CDP raises prices. The company's entire AI stack is hostage to that vendor relationship. Migrating means rebuilding the data layer from scratch, because the schemas, the models, and the semantic definitions all sit inside the vendor's infrastructure. What looked like a quick path to activation has turned into a long-running lock-in.
5. A flywheel of compounding intelligence
The most successful businesses with customer-facing AI will be the ones that learn the fastest. Their agents will learn through experience what works and what doesn't, with different customers as individuals and as segments. That learning compounds into better service, which compounds into better outcomes, which compounds into a competitive position competitors can't replicate.
For the flywheel to spin, decisions made by agents working on the customer context layer have to be captured back into the layer. Every recommendation, every intervention, every personalization is itself a behavioral event. Those events feed the next decision, and the cycle closes.
The flywheel is built on your first-party behavioral data, which is the institutional knowledge of how your customers actually behave with your product and digital estate. Nobody else has that data. The longer you run the layer, the further ahead you get.
Failure mode. An ecommerce company deploys a shopper agent but never instruments the measurement leg. There's no feedback loop connecting agent interactions back to outcomes in the warehouse. The agent keeps recommending products, but conversion rate stays flat. Nobody can tell whether the agent is helping or hurting, which product categories it's getting wrong, or why a cohort of high-value customers stopped engaging. Meanwhile, competitors who closed the loop are improving their models every week. The gap widens, and nobody sees it happening.
6. Deployable in days, not quarters
Agents move faster than the people building the layer they run on. So the layer has to keep up. Standing the layer up shouldn't take a multi-quarter engineering program. Iterating on it shouldn't take another quarter every time the product team ships a new feature. Tracking design, schema evolution, debugging, infrastructure management. Data teams should be able to do all of this through AI-driven workflows in tools they already use. Days for the initial deploy, and minutes for the ongoing iteration after that.
If your customer context layer takes a year to stand up and six months to update every time a new feature ships, your product will outrun the layer. And a layer that can't keep up with the product can't keep an agent grounded.
Failure mode. An insurance company decides to build its customer context layer in-house. Six months on collection infrastructure. Three more on schema governance tooling. Another quarter on identity resolution. By the time they get to real-time delivery and agent-readable formatting, the product has shipped four major features that aren't tracked. The AI team has been waiting eight months for data they were promised in two. The original engineers have moved on.
Why this matters now
Consumer expectations of AI are rising fast. Almost everyone uses ChatGPT, Claude, or something like them, and those experiences set the bar for what a useful AI feels like. Customers carry that bar into every interaction with your product.
If your AI doesn't meet it, customers will feel the gap immediately. More and more of them will start using their own AI agents to interact with you on their behalf, and they'll look elsewhere when the experience falls short.
The data foundation is what makes the difference. The businesses shipping AI experiences customers actually trust over the next eighteen months will be the ones that built a customer context layer rich enough, fast enough, and grounded enough to keep pace with what their customers now expect. Model choice matters a lot less than that foundation.
This is the first piece in the Customer Context Layer series. Over the coming weeks we'll look at why customer-facing AI agents need more than a semantic layer, how a customer context layer and a semantic layer work together, the integration pattern between a customer context layer and Snowflake Intelligence, the same for Databricks AI/BI Genie, and how existing Snowflake and Databricks customers are running one in production today.
Snowplow is the customer context layer
At Snowplow we've been building this infrastructure for years. Today, Snowplow is the customer context layer for businesses that want to ground their AI agents in real-time customer behavior they own. The layer runs inside your own cloud account, in open data formats, with schemas your data team owns. It collects behavioral events from every customer-facing surface, validates them at source, resolves identity in real time across sessions and devices (including the AI agents acting on customers' behalf), and lands the data in your warehouse for analytics agents to use downstream. Snowplow Signals serves the same context in real time to ML models and customer-facing agents through a sub-second API and a profile store.
Snowplow runs on AWS, Azure, and GCP. Data lands in Snowflake, Databricks, or BigQuery. Signals runs on Snowflake and BigQuery today, with Databricks support coming.
You can try Snowplow for free with our new 14-day trial. If you’d like to learn more about Snowplow, contact our team for a no-obligation chat.
For the longer read on how this connects to the architectural shift Brinker describes, Alex Dean's Databricks guest post walks through the customer context layer as a complement to The New Martech Stack report.
Frequently asked questions about the customer context layer
What is a customer context layer?
A customer context layer is the infrastructure between your data platform and your customer-facing AI applications. It collects behavioral events from every surface a customer touches, resolves identity in real time (including AI agents acting on the customer's behalf), and delivers structured context to AI agents in a form they can reason over. The same data lands in your warehouse for analytics agents to use downstream.
Why do AI agents need a customer context layer?
AI agents are only as good as the context they reason over. Without a customer context layer, agents work from stale, warehouse-aggregated data that does not reflect what the customer is doing right now. That produces unreliable outputs and erodes customer trust at scale.
How is a customer context layer different from a semantic layer?
A semantic layer describes what the data in your warehouse means. It tells an analytics agent what "conversion" means, or how "active user" is calculated. A customer context layer feeds the semantic layer the real-time behavioral signal those definitions point at. The two work together.
How is a customer context layer different from a CDP?
A CDP collects customer records and pushes them to marketing engagement tools like email service providers, ad platforms, and website experiences. It’s more narrowly focused on marketing activation, whereas a customer context layer underpins your entire customer-facing digital estate. It collects behavioral context, what a customer is doing across your digital estate right now, and serves it to customer-facing agents in real time and analytics agents through the warehouse.
How is a customer context layer different from a feature store?
A feature store serves pre-computed features to machine learning models on a scheduled cadence. A customer context layer serves real-time, identity-resolved behavioral context to AI agents that need to act in the current session. The two complement each other.
What is context engineering, and how does it relate to a customer context layer?
Context engineering is the discipline of assembling the right information for an AI agent to act on, named by Andrej Karpathy and Tobi Lütke through 2025 as the work that replaces prompt engineering for production agents. A customer context layer is the productized form of that discipline, applied to customer-facing AI.
How does a customer context layer work with Snowflake or Databricks?
A customer context layer runs alongside your enterprise data platform and feeds it validated, identity-resolved behavioral data. Customer-facing agents draw on the layer in real time. Analytics agents like Snowflake Intelligence and Databricks AI/BI Genie reason over the same data once it has landed in the warehouse.