

Documentation
Forwarding Events to Downstream Destinations
Trigger downstream actions instantly with enriched, low-latency behavioral data—delivered in real time from your Snowplow pipeline to any system.

Stream events in real time to internal systems or external platforms, empowering teams to take action as customer behaviors unfold.
Create and manage data forwarding workflows directly in your Snowplow Console. Define which events to transform and send, all in a few clicks.
Forward only validated, enriched events - no raw or partial data - preserving data quality and trust across real-time workflows within your technology stack.
Event Forwarding allows teams to act on behavioral data the moment it’s generated, whether for real-time analytics, marketing campaign triggers, or internal stream processing. Events are enriched upstream and delivered to SaaS applications and stream destinations via pre-built API integrations.
Power user journeys and marketing personalization in real time
Detect risky behaviors or fraudulent activity to trigger alerts
Enable event-driven microservices with low latency

Integrate Snowplow’s governed behavioral data to the tools and systems your teams rely on, whether that’s out-of-the-box integrations with Braze, Amplitude, Mixpanel or custom connections via HTTP API destinations. These integrations are ready to use with minimal setup, bringing immediate value to business teams.
Stream to native destinations such as Braze and Amplitude in real time
Deliver enriched, ready-to-use JSON events for downstream processing
Reduce engineering effort to build and maintain custom integrations

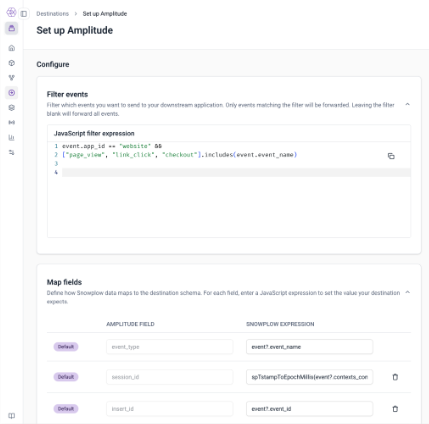
Give teams the flexibility to shape and filter data using custom JavaScript expressions directly within the Console. Define precise logic for which events to forward, how to map fields to destination schemas, and apply real-time transformations without additional tooling.
Simplified setup within the Snowplow Console UI
Full transparency and control over schema and payload
Test transformations to ensure downstream compatibility
Both Kafka and Kinesis support real-time event streaming, but they serve different needs:
Snowplow works seamlessly with both, depending on infrastructure preference and operational needs.
Yes, Azure Event Grid can effectively integrate with Snowplow's event forwarding capabilities to create sophisticated event-driven architectures.
Event Grid integration:
Scalability and reliability:
Building a pub/sub architecture with Kafka for product analytics enables scalable, real-time insights into user behavior and product performance.
Topic design and organization:
Producer setup:
Consumer and processing:
Visualization and activation:
Implementing robust error handling for failed Snowplow events ensures no data loss and enables systematic reprocessing.
Dead-letter queue setup:
Azure Blob Storage integration:
Automated reprocessing workflows:
To use Kafka as a destination for Snowplow event forwarding, follow these steps:- Configure Snowplow to forward events to Kafka topics via the Kafka producer API.- Set up Kafka topics to receive the event data from Snowplow.- Ensure that data is consumed by downstream applications or storage systems that will process the events.
Create a live trial environment, send your first events, then work with it from your own coding tool through the MCP server or ask Snowplow Assistant in the console. No expert required, no credit card, no sales call.

