
Using AWS Glue and AWS Athena with Snowplow data
This is a guide to interacting with Snowplow enriched events in Amazon S3 with AWS Glue.
The objective is to open new possibilities in using Snowplow event data via AWS Glue, and how to use the schemas created in AWS Athena and/or AWS Redshift Spectrum.
This guide consists of the following sections:
- Why analyze Snowplow enriched events in S3?
- AWS Glue prerequisites
- Creating the source table in Glue Data Catalog
- Optionally format shift to Parquet using Glue
- Use AWS Athena to access the data
- Use AWS Redshift Spectrum to access the data
- Next steps
1. Why analyze Snowplow enriched events in S3?
Analyzing the Snowplow data on S3 may be useful in a number of scenarios, for instance:
- One common reason is when the data that is needed is no longer on Redshift because the data owner only keeps the most recent data in Redshift (e.g. if the data owner is dropping all but the last month of data to save space).
- Another possibility is that the user would like to get a special subset of the data onto S3 and make it available for a specific use.
- Yet another motivation, may be to run a very large query on all history without affecting a resource constrained Redshift cluster.
In all those scenarios one or both of the following examples may be useful.
For instance to get back deleted data from S3, one may use the Redshift Spectrum example to query the archive and even insert the query result into a new table.
In the case of the resource constrained Redshift Cluster, the data owner may elect to run the query on Athena.
The optional parquet step is there in case you are planning to use the archive often, in which case performance would be important, so a way to create a copy of the archive in parquet is shown. Parquet is an efficient, columnar, Hadoop file format which is ideally suited to that use case.
If that is what you are trying to do you may want to also want to look into triggers for the Glue script, which will enable you to keep the parquet copy up to date.
In order to develop these examples we will use a hypothetical scenario, in which we want to analyze Snowplow enriched events by extracting a certain context from the contexts field.
Specifically, we will the context with schema iglu:org.w3/PerformanceTiming/jsonschema/1-0-0. That context contains performance information about page loading and the hypothetical analyst would like to obtain that data as a table, perhaps in order to correlate performance with something else (e.g. a new version of the website being release, and how that affects performance).
In both cases we will need to create a schema in order to read in the data which are formatted in Snowplow’s Enriched Event format, which is covered in the schema setup step below, which has its requirements outlined in the prerequisites step.
Finally, you can follow either one or both of the Athena or Redshift Spectrum steps to achieve that goal.
2. AWS Glue prerequisites
Setting up Glue, Glue Data Catalog and their assorted IAM policies is beyond the scope of this guide, but the main prerequisite units are mentioned here along with links to guides to set up everything, before you start following this guide.
As we want to create a schema in some metastore that is shared across all the frameworks we are using, we are going to use the AWS Data Catalog. Also we will need appropriate permissions and aws-cli.
Setup Data Catalog in Athena
In order to use the created AWS Glue Data Catalog tables in AWS Athena and AWS Redshift Spectrum, you will need to upgrade Athena to use the Data Catalog.
Please familiarize yourself with what that means by reading the relevant FAQ.
Once you are happy with that change, carry out the upgrade by following the relevant step-by-step guide.
IAM Service Role
You will also need to have an appropriate IAM role for glue that can read from your snowplow archive S3 location and, if following the optional step, write to the output.
Please follow steps 1 and 2 from the AWS Glue getting started guide, which you can find here and here.
Setup AWS Cli
You will also need to have aws cli set up, as some actions are going to require it.
Please follow the excellent AWS documentation on AWS to get it set-up for your platform, including having the correct credentials with Glue and S3 permissions.
3. Creating the source table in AWS Glue Data Catalog
In order to use the data in Athena and Redshift, you will need to create the table schema in the AWS Glue Data Catalog.
To do that you will need to login to the AWS Console as normal and click on the AWS Glue service. You may need to start typing “glue” for the service to appear:

Creating the database
Then you will need to add a database by clicking on “Databases” from the left pane and then the “Add Database” button:

Set a database name in the dialog (we will use snowplow_data as the database name for the rest of this article)
You can also perform that step using the CLI with:
aws glue create-database --database-input '{"Name": "snowplow_data", "Description": "Snowplow Data"}'
Creating the archive table
In order to create the table, you will need to use the CLI as creating all the fields (~130) would be too error-prone and tedious using the console.
Use a command like so:
aws glue create-table --database-name snowplow_data --table-input ' { "Name": "archive", "Owner": "owner", "Retention": 0, "StorageDescriptor": { "Columns": [ { "Name": "app_id", "Type": "string" },
Full code can be found here
After this step you will have the table definition exists that can be used with Glue, Athena and Redshift, however you will need to update the partitions every time the underlying data changes (e.g. new data arrives).
One way of doing that is to run the following SQL on Athena:
MSCK REPAIR TABLE archive
Unless you have the correct partitions in the metastore you will not be able to query all (or any) of the Snowplow data using that table definition (even though the data is there).
The alternative is to not specify partition keys in the definition above by setting "PartitionKeys": [] but that will prevent using that table definition in Glue in some cases (however you will be able to use it in Athena and Spectrum), such as in the Parquet example below.
4. Optionally format shift to Parquet using Glue
The optional second step is there in case you are planning to use the archive often, in which case performance would be important. A way to create a copy of the archive in Parquet is shown, which is an efficient, columnar, Hadoop file format.
This step is optional and only makes sense if you want to create a Parquet version of the archive for frequent efficient use.
A prerequisite for this step is that you have created a partition key on Step 1.
If you choose to perform this step, you can use archive_parquet wherever you see the archive table being used on the subsequent steps.
Ensure that the data partitions have been created
In order to run this step you will need to ensure that the data partitions have been updated by running:
MSCK REPAIR TABLE archive
on the Athena page. Ensure that you have selected snowplow_data as the database and that the archive table is shown as (Partitioned) like so:

Which should result in an output like this if successful:

Setup a simple Parquet job to format shift to Parquet
Back on the Glue page, click on “Jobs” from the left pane and then the “Add job” button:

On the Add job workflow, choose the appropriate name for the job and an IAM role that can access both the intended input and output locations, and select “A proposed script generated by AWS Glue” and “Python” and click “Next”:

On “Choose your data sources” simply choose the “archive” table from the “snowplow_data” database and click “Next”:

On “Choose your data targets” select “Create tables” on “S3” using the “Parquet format” and selecting an appropriate location on S3 where you want the parquet data, like so:

and click “Next”.
In the “Map the source columns to target columns” accept the default (you should see a 1-1 mapping of all the fields) mappin
g and click “Next”.
Finally review and click “Save job and edit script”.
The screen should then look like this:
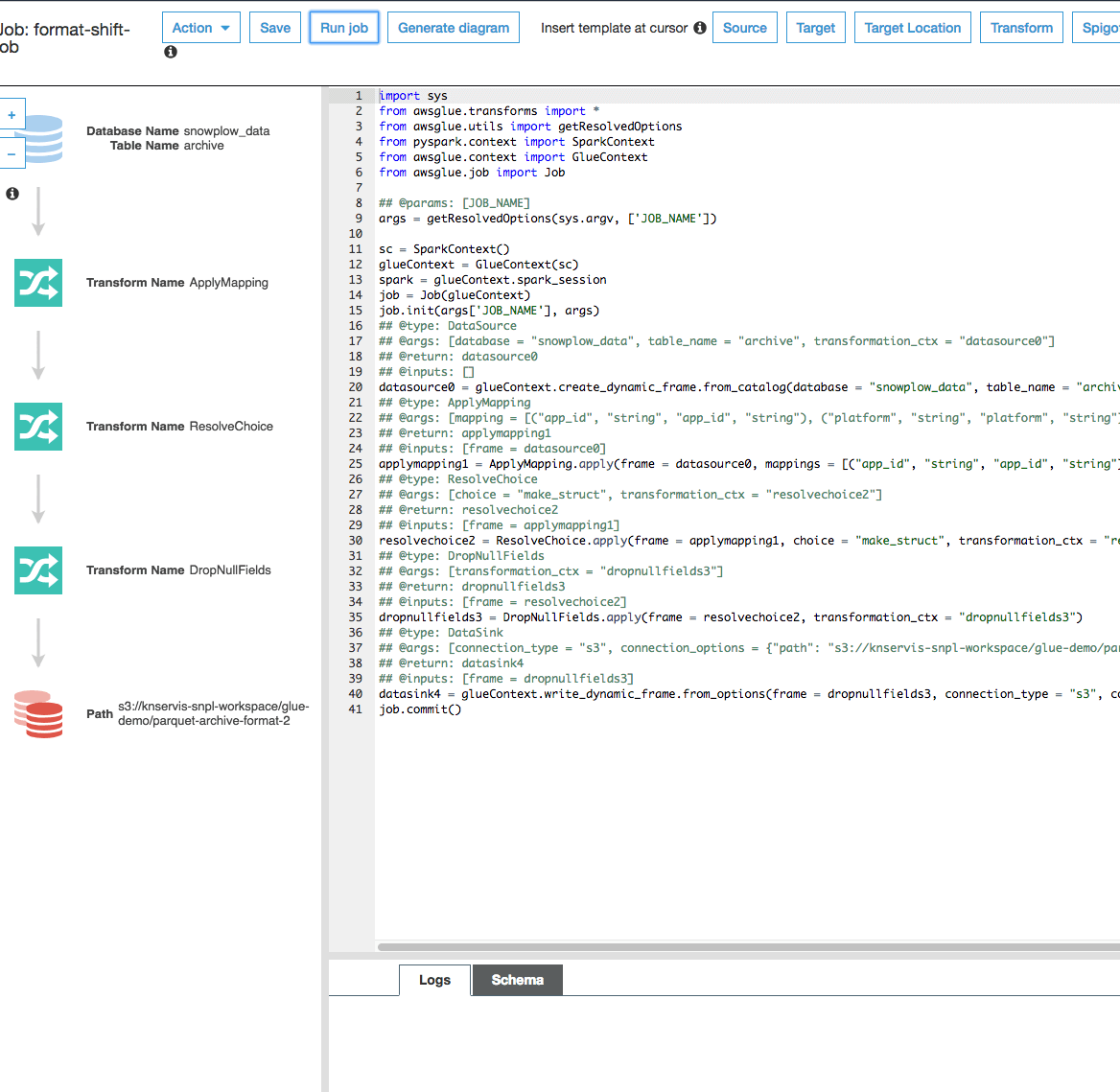
And you can click on “Run job”.
Once the job is finished (you can monitor the progress on the bottom of the screen under “Logs”), you should have created a number of files in your chosen location, with the suffix snappy.parquet (e.g. s3://your-output-bucket/your-chosen-prefix/part-00136-b2b9d533-88bc-4307-a2a6-a452a459fe85-c000.snappy.parquet).
Create table definition for your parquet data
Finally you will need to create a table definition for the new data using:
aws glue create-table --database-name snowplow_data --table-input ' { "Name": "archive_parquet", "Owner": "owner", "Retention": 0, "StorageDescriptor": { "Columns": [ { "Name": "app_id", "Type": "string" },
Full code can be found here
If you have gone through this step, remember to use archive_parquet table instead of archive in the subesquent steps.
5. Use AWS Athena to access the data
Keeping your Parquet data up-to-date
You may want to also want to look into triggers for the Glue script, which will enable you to keep the parquet copy up to date.
Now that you have a Data Catalog entry that you can use, head over to the Athena console and select snowplow_data as the database for our new query in the “Query Editor”:

Now in the “query editor” you can try using the new table.
Below is an example query that you can run on Athena to access your data.
That query extracts a context that matches the iglu:org.w3/PerformanceTiming/jsonschema/1-0-0 iglu schema out of the contexts field and then extracts the individual fields out of that context.
At the time of writing, due to a limitation of the Data Catalog this cannot be turned into a view.
SELECT json_extract(performance_events[1], '$.data.navigationStart') AS navigationStart, json_extract(performance_events[1], '$.data.unloadEventStart') AS unloadEventStart, json_extract(performance_events[1], '$.data.unloadEventEnd') AS unloadEventEnd, json_extract(performance_events[1], '$.data.redirectStart') AS redirectStart, json_extract(performance_events[1], '$.data.redirectEnd') AS redirectEnd, json_extract(performance_events[1], '$.data.fetchSta
rt') AS fetchStart, json_extract(performance_events[1], '$.data.domainLookupStart') AS domainLookupStart, json_extract(performance_events[1], '$.data.domainLookupEnd') AS domainLookupEnd, json_extract(performance_events[1], '$.data.connectStart') AS connectStart, json_extract(performance_events[1], '$.data.connectEnd') AS connectEnd, json_extract(performance_events[1], '$.data.secureConnectionStart') AS secureConnectionStart, json_extract(performance_events[1], '$.data.requestStart') AS requestStart, json_extract(performance_events[1], '$.data.responseStart') AS responseStart, json_extract(performance_events[1], '$.data.responseEnd') AS responseEnd, json_extract(performance_events[1], '$.data.domLoading') AS domLoading, json_extract(performance_events[1], '$.data.domInteractive') AS domInteractive, json_extract(performance_events[1], '$.data.domContentLoadedEventStart') AS domContentLoadedEventStart, json_extract(performance_events[1], '$.data.domContentLoadedEventEnd') AS domContentLoadedEventEnd, json_extract(performance_events[1], '$.data.domComplete') AS domComplete, json_extract(performance_events[1], '$.data.loadEventStart') AS loadEventStart, json_extract(performance_events[1], '$.data.loadEventEnd') AS loadEventEnd, json_extract(performance_events[1], '$.data.chromeFirstPaint') AS chromeFirstPaint FROM ( SELECT FILTER(CAST(json_extract(contexts, '$.data') AS ARRAY(JSON)), x -> regexp_like(json_extract_scalar(x, '$.schema'), 'iglu:org.w3/PerformanceTiming/jsonschema/1-0-0')) AS performance_events FROM archive ) WHERE cardinality(performance_events) = 1;
(CREATE VIEW with the above is currently not supported due to ARRAY(JSON) but it probably should be)
For further details on what is and what isn’t supported read the excellent AWS documentation, including unsupported DDL in Athena.
6. Use AWS Redshift Spectrum to access the data
Just as with the previous step, you will need to create an appropriate role that can access your data, which you can do by following the IAM Role guide here
Create external schema
In order to use the table create in Data Catalog, you will need to create an external schema using the IAM role that you have created, using:
create external schema glue_schema from data catalog database 'snplow-enriched-archive' iam_role 'arn:aws:iam::719197435995:role/konstantinos-RS-load;
For more background on external schemas, read the excellent AWS documentation on that topic.
Using the table
Finally, for the same scenario as with Athena above, in order to isolate a single context and extract its fields you would do something like this:
CREATE OR REPLACE VIEW performanceEvents AS SELECT navigationStart, unloadEventStart, unloadEventEnd, redirectStart, redirectEnd, fetchStart, domainLookupStart, domainLookupEnd, connectStart, connectEnd, secureConnectionStart, requestStart, responseStart, responseEnd, domLoading, domInteractive, domContentLoadedEventStart, domContentLoadedEventEnd, domComplete, loadEventStart, loadEventEnd, chromeFirstPaint FROM (SELECT json_extract_path_text(contexts, 'data') AS data, json_extract_array_element_text(data,0) AS elem_0, json_extract_array_element_text(data,1) AS elem_1, json_extract_array_element_text(data,2) AS elem_2, json_extract_array_element_text(data,3) AS elem_3, json_extract_array_element_text(data,4) AS elem_4, json_extract_array_element_text(data,5) AS elem_5, CASE WHEN REGEXP_INSTR(elem_0, 'iglu:org.w3/PerformanceTiming/jsonschema/1-0-0') > 0 THEN elem_0 WHEN REGEXP_INSTR(elem_1, 'iglu:org.w3/PerformanceTiming/jsonschema/1-0-0') > 0 THEN elem_1 WHEN REGEXP_INSTR(elem_2, 'iglu:org.w3/PerformanceTiming/jsonschema/1-0-0') > 0 THEN elem_2 WHEN REGEXP_INSTR(elem_3, 'iglu:org.w3/PerformanceTiming/jsonschema/1-0-0') > 0 THEN elem_3 WHEN REGEXP_INSTR(elem_4, 'iglu:org.w3/PerformanceTiming/jsonschema/1-0-0') > 0 THEN elem_4 WHEN REGEXP_INSTR(elem_5, 'iglu:org.w3/PerformanceTiming/jsonschema/1-0-0') > 0 THEN elem_5 ELSE NULL END AS performance_event, json_extract_path_text(performance_event, 'data') AS performance_event_data, json_extract_path_text(performance_event_data, 'navigationStart') AS navigationStart, json_extract_path_text(performance_event_data, 'unloadEventStart') AS unloadEventStart, json_extract_path_text(performance_event_data, 'unloadEventEnd') AS unloadEventEnd, json_extract_path_text(performance_event_data, 'redirectStart') AS redirectStart, json_extract_path_text(performance_event_data, 'redirectEnd') AS redirectEnd, json_extract_path_text(performance_event_data, 'fetchStart') AS fetchStart, json_extract_path_text(performance_event_data, 'domainLookupStart') AS domainLookupStart, json_extract_path_text(performance_event_data, 'domainLookupEnd') AS domainLookupEnd, json_extract_path_text(performance_event_data, 'connectStart') AS connectStart, json_extract_path_text(performance_event_data, 'connectEnd') AS connectEnd, json_extract_path_text(performance_event_data, 'secureConnectionStart') AS secureConnectionStart, json_extract_path_text(performance_event_data, 'requestStart') AS requestStart, json_extract_path_text(performance_event_data, 'responseStart') AS responseStart, json_extract_path_text(performance_event_data, 'responseEnd') AS responseEnd, json_extract_path_text(performance_event_data, 'domLoading') AS domLoading, json_extract_path_text(performance_event_data, 'domInteractive') AS domInteractive, json_extract_path_text(performance_event_data, 'domContentLoadedEventStart') AS domContentLoadedEventStart, json_extract_path_text(performance_event_data, 'domContentLoadedEventEnd') AS domContentLoadedEventEnd, json_extract_path_text(performance_event_data, 'domComplete') AS domComplete, json_extract_path_text(performance_event_data, 'loadEventStart') AS loadEventStart, json_extract_path_text(performance_event_data, 'loadEventEnd') AS loadEventEnd, json_extract_path_text(performance_event_data, 'chromeFirstPaint') AS chromeFirstPaint FROM glue_schema.archive WHERE performance_event IS NOT NULL) WITH NO SCHEMA BINDING;
You may of course insert the data into another table in redshift for better performance.
7. Next steps
So far we have seen how to use AWS Glue and AWS Athena to interact with Snowplow data. We have seen how to create a Glue job that will convert the data to parquet for efficient querying with Redshift and how to query those and create views on an iglu defined event.
We encourage you to experiment with those tools and if they are suitable to your workflow you can consider adding an scheduled or triggered Glue job to perform those tasks as new data comes in.
If you have any question regarding this guide or you need help with how you could use your Snowplow events with Athena, Glue and Redshift, please visit our Discourse forum.