
Google Cloud Dataflow example project released
We are pleased to announce the release of our new Google Cloud Dataflow Example Project!
This is a simple time series analysis stream processing job written in Scala for the Google Cloud Dataflow unified data processing platform, processing JSON events from Google Cloud Pub/Sub and writing aggregates to Google Cloud Bigtable.
The Snowplow GCP Dataflow Streaming Example Project can help you jumpstart your own real-time event processing pipeline on Google Cloud Platform (GCP). In this release post we will take you through the steps to get this simple analytics-on-write job setup and processing your Pub/Sub event stream.
Read on after the fold for:
- What are Google Cloud Dataflow and Pub/Sub and why are we using them?
- Introducing analytics-on-write
- Detailed setup
- Our next steps with Google Cloud Platform
1. What are Google Cloud Dataflow and Pub/Sub and why are we using them?
One of the priorities for Snowplow in 2017 is extending our software to run on public clouds other than AWS, such as Google Cloud Platform and Microsoft Azure, and to run on-premise using Apache Kafka. Two major goals for this are:
- Broadening Snowplow adoption - we want Snowplow to be available to companies on whichever cloud or on-premise architecture they have adopted
- Offering “pipeline portability” - investing in Snowplow shouldn’t lock you into a specific cloud platform indefinitely. You should be able to bring the core capabilities - and data - of your Snowplow pipeline with you when you migrate from one cloud to another
When we are exploring a new technology or platform, we like to start by open-sourcing a simple example project (like our Spark Example Project or our AWS Lambda Node.js Example Project). Tasked with learning more about Google Cloud Platform, we set out to create an example project using some of GCP’s APIs and services that are most likely to be used by a Snowplow port. That way, both our team and our community get familiarized with aspects of that ecosystem, specifically:
Google Cloud Dataflow
Google Cloud Dataflow is both the name of a unified model for batch and streaming data processing and a GCP managed service for executing data processing jobs using that model.
Google Cloud Pub/Sub
Google Cloud Pub/Sub is a fully-managed messaging middleware, that allows you to interconnect several components of a complex (data processing) system, enable real-time communication between them. It implements a Publisher-Subscriber communication model.
2. Introducing analytics-on-write
This example project is a simple analytics-on-write job - the kind of event analytics that could occur in a real-life event data pipeline. Our Dataflow job reads a Pub/Sub topic containing events in a JSON format:
{ "timestamp": "2015-06-05T12:54:43.064528", "type": "Green", "id": "4ec80fb1-0963-4e35-8f54-ce760499d974" }
Our job counts the events by type and aggregates these counts into 1 minute buckets. The job then takes these aggregates and stores them into a table in Google Cloud Bigtable.
There are two major steps in our job:
- Downsampling: where we reduce the event’s ISO 8601 timestamp down to minute precision, so for instance “2015-06-05T12:54:43.064528” becomes “2015-06-05T12:54:00.000000”. This downsampling gives us a fast way of bucketing or aggregating events via this downsampled key
- Bucketing: an aggregation technique that builds buckets, where each bucket is associated with a downsampled timestamp key and an event type criterion. By the end of the aggregation process, we’ll end up with a list of buckets - each one with a countable set of events that “belong” to it.
3. Detailed setup
In this tutorial, we’ll walk through the process of getting up and running with GCP Pub/Sub and Dataflow. You will need git, Vagrant and VirtualBox installed locally.
Step 1: Build the project
In your local terminal, set up and ssh into your Vagrant box. This should take around 10 minutes with these commands:
host$ git clone https://github.com/snowplow/google-cloud-dataflow-example-project host$ cd google-cloud-dataflow-example-project host$ vagrant up && vagrant ssh
Let’s now build the project:
guest$ cd /vagrant guest$ inv build_project
Step 2: Setup project and authenticate
You’re going to need credentials to run certain parts of this project. You’ll also need to create a new project in GCP and enable some APIs/services:
- Cloud Dataflow
- Cloud Pub/Sub
- Cloud Storage
- Cloud Bigtable
There’s a guide on Snowplow’s wiki on how to setup a GCP project and enable APIs/services.
After enabling these services, authenticate with your GCP account by running the following commands:
guest$ gcloud auth login guest$ gcloud auth application-default login guest$ gcloud config set project $YOUR_PROJECT_ID
These will prompt links you’ll have to follow on your host OS, which will allow you to use your browser to authenticate.
Step 3: Create your Pub/Sub topic
We’re going to set up the Pub/Sub topic. Your first step is to create a topic and verify that it was successful. Use the following command to create a topic named “test-topic”:
$ inv create_pubsub_topic --topic-name=test-topic
Step 4: Create a Bigtable table for storing our aggregates
We’re using “test-table” as the table name, “test-instance” as the instance name and “cf1” as the column family. Bigtable is a NoSQL clustered database. It has the concept of column families: groups of columns that are related and as such, are likely to be accessed roughly at the same time. In the context of this project, all the columns will live in the same column family.
Invoke the creation of the table with:
$ inv create_bigtable_table --instance-id=test-instance --region=us-west1-a --table-name=test-table --column-family=cf1
Step 5: Create a staging location for Dataflow
Dataflow needs a place to store the jarfile that it will use to run our job. This is called the staging location.
To create one for your project, go to https://console.cloud.google.com/storage/browser?project=YOUR-PROJECT-ID and click “Create Bucket”. Fill in the appropriate details. As this is an example project, we suggest you pick the cheapest option:

After creating your bucket, you might want to create a folder inside it, to serve as your staging location; you can also just use the bucket’s root. To create a folder in your bucket, after you created the bucket, select it in the list and then click “Create Folder”.
Your staging location will be:
gs://your-bucket-name/your-folder

Step 6: Submit your application to Dataflow
Before you can run your application, you’ll need to setup a proper config file. There’s an example in config/config.hocon.sample. If you’ve been using the same names as we did, you’ll only need to perform some minimal changes, specifically:
- Updating the project ID
- Updating the Pub/Sub topic’s full name
- Updating the staging location in Cloud Storage to upload the fat jar to
Then, inside your Vagrant box run (assuming you’ve built the project, as instructed. Alternatively, you can download it from Bintray):
guest$ inv run_project --config=path/to/config/file --fat-jar-path=path/to/fat.jar
This will submit your job to Dataflow.
Step 7: Generate events in your Pub/Sub Topic
After you’ve submitted your job to Dataflow, it’s time to generate some events in our Pub/Sub Topic:
$ inv generate_events --topic-name=test-topic --nr-events=<some-number> Event sent to Kinesis: {"timestamp": "2015-06-05T12:54:43.064528", "type": "Green", "id": "4ec80fb1-0963-4e35-8f54-ce760499d974"} Event sent to Kinesis: {"timestamp": "2015-06-05T12:54:43.757797", "type": "Red", "id": "eb84b0d1-f793-4213-8a65-2fb09eab8c5c"} Event sent to Kinesis: {"timestamp": "2015-06-05T12:54:44.295972", "type": "Yellow", "id": "4654bdc8-86d4-44a3-9920-fee7939e2582"} ...
If you leave out the --nr-events parameter, the event generator will run on an infinte loop (to kill it, Ctrl+C)
Step 8: Monitor your job in the Dataflow UI
Now there are two places we want to check to see if everything is running smoothly.
The first place is Dataflow’s web interface. Go to https://console.cloud.google.com/dataflow?project=YOUR-PROJECT-ID and select the job you just submitted. You should then see a graph with the several transforms that make up our data pipeline:

You can click on the transforms to get specific info about each one, such as their throughput. If something is not working properly, you’ll get warnings under “Logs”. You can also check the central log in: https://console.cloud.google.com/logs?project=YOUR-PROJECT-ID Remember to change YOUR-PROJECT-ID to the appropriate value in these URLs.
Step 9: Review your data in Bigtable
The second place you’ll want to check is your Bigtable table. To do so, you’ll need to use HBase, and we suggest you to do it inside your Google Cloud Shell (reference.
To access your Google Cloud Shell, go to your Google Cloud Dashboard (https://console.cloud.google.com/home/dashboard?project=YOUR-PROJECT-ID) and click on the little terminal symbol on the top right corner. That will boot your shell. Wait for it to become available, then:
google-shell$ curl -f -O https://storage.googleapis.com/cloud-bigtable/quickstart/GoogleCloudBigtable-Quickstart-0.9.5.1.zip google-shell$ unzip GoogleCloudBigtable-Quickstart-0.9.5.1.zip google-shell$ cd quickstart google-shell$ ./quickstart.sh
This will boot your HBase shell, which you’ll use to interact with your Bigtable table. At this point, you can run (assuming your table is named “test-table”):
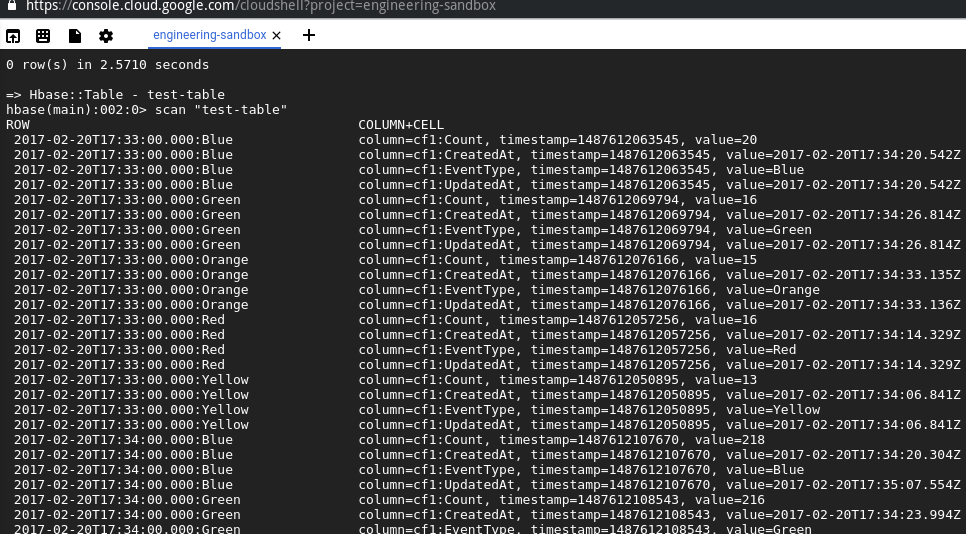
hbase-shell> scan "test-table"
This will print the rows in your table, where you can see the counts for each bucket and type:
Step 10: Shut everything down
Remember to shut off:
- Python event generator
- Bring down all the resources used on GCP. To do this you can either delete your project (recommended) or you can manually:
- Halt your Dataflow job
- Delete your Pub/Sub topic
- Delete your Bigtable table
- Delete your staging location and bucket
- Exit your Vagrant guest
vagrant haltvagrant destroy
And that’s it! You have successfully run your first streaming analytics job on Google Cloud Platform. Along the way you gained some familiarity with GCP in general, and the Cloud Dataflow, Cloud Pub/Sub and Cloud Bigtable services in particular.
4. Our next steps with Google Cloud Platform
Our experiments with GCP to-date have left us impressed by the platform and the various data services that it offers; we are very excited about the opportunities for running Snowplow on Google Cloud Platform making idiomatic use of these services.
Our next step is to put together a Request for Comments on our Discourse, to set out our proposal for porting Snowplow to GCP. Stay tuned! And if in the meantime you have any questions about this tutorial, do please let us know.