
Batch Processing vs. Stream Processing: What’s the Difference and When to Use Each?
Organizations are increasingly adopting data products to improve their business operations. As part of this shift, selecting the right data processing approach has become critical to building scalable and cost-effective modern data platforms.
For data teams, knowing when to use stream processing versus batch processing can significantly impact performance and cost. Making the right choice allows teams to allocate budgets more effectively—investing in real-time processing where speed adds value, and leveraging batch jobs where it’s more cost-efficient.
In this blog post, we will cover:
- Definitions of batch and stream processing
- Highlight their key differences and trade-offs
- Review when to use each with relevant use cases
- Examine important implementation considerations
- Outline strategies for cost optimization
We will also relate these topics to contemporary infrastructures, including Snowplow's lakehouse and streaming solutions.
What is Batch Processing vs Stream Processing?
Batch processing and stream processing represent the two main categories used to classify data processing methods.
- Batch processing: A method where large volumes of data are collected over time and processed in batches at scheduled intervals, typically involving data warehouses and ETL processes for historical analysis.
- Stream processing: A paradigm that analyzes data continuously in real time as it flows through the system, enabling immediate insights and actions on live data streams.
Batch Processing
The primary characteristic of batch processing is its focus on gathering a substantial volume of data over an extended period. A batch processing task can either be a single job performed on a large dataset or a recurring job that takes place at longer intervals, such as once daily.
Due to the emphasis on gathering data over time, the batches managed by batch processing can be quite large, resulting in more profound insights with each execution of the batch processing job.
Stream Processing
The primary focus of stream processing, on the other hand, is a processor that operates on data in real time as it is generated, rather than waiting for data to gather in batches. Data "events," which represent specific occurrences that require analysis, reach the stream processor almost immediately after the event occurs, allowing the stream processing to react to that event or include it in its analytical outcomes with very little delay.
A data-mature organization uses both stream and batch processing in various situations, capitalizing on the unique advantages each method provides.
As a modern customer data infrastructure platform, Snowplow supports both paradigms. This is crucial for equipping data teams with the necessary tools to develop solutions that harness the benefits offered by each approach.
Why is Understanding Batch vs Stream Processing Important?
The amount of data generated worldwide is constantly rising. The global Big Data and Analytics Market is projected to reach USD 393 billion in 2025, with continuous growth each year. Across all key sectors, businesses are progressively utilizing data to obtain insights that provide a competitive edge over their competitors.
Against this backdrop of growing reliance on data, it is essential for data-driven organizations to have access to flexible, low-cost infrastructure solutions and to utilize them efficiently when deploying data processing products.
The decision of when to use batch or stream processing is a vital choice. It affects your organization's capacity to manage, analyze, and respond to data, impacting aspects ranging from operational efficiency to business decision-making and technology investments.
- Performance impact: Batch and stream processing yield varying outcomes regarding latency, throughput, and consequently, the end user experience.
- Cost implications: Cost is the counterpart to performance. When deciding between batch and stream processing, it is essential to be pragmatic about the budget at your disposal to fulfill your product needs, weighed against the benefits of pursuing low-latency options.
- Scalability considerations: Both approaches can scale to handle large volumes of data, though they come with different trade-offs and implementation considerations.
- Business value: The best choice between batch and stream processing depends on whether your use case benefits more from real-time event data or if it is more important to provide a comprehensive historical analysis.
Key Differences Between Batch and Stream Processing
Latency
A significant distinction between the two methods is the latency associated with data availability for querying.
In batch processing, minimizing data latency is not the primary focus. Data is processed at predetermined intervals, which could be hourly or daily, leading to relatively high data latency.
Conversely, stream processing involves continuous data processing, enabling real-time data solutions with very low latency.
Volume
Another distinction between the methods lies in their approach to managing large volumes of data.
In batch processing, a scheduled job must handle all the data collected since the last execution. Typically, a batch job addresses this by dividing the batch into smaller, manageable segments, processing each segment, and compiling the results.
In contrast, stream processing cannot break the data into smaller pieces, as it needs to process the incoming data in real time. To enhance the capacity of a stream processing job, you can divide the stream into smaller parts–called shards–and implement horizontal scaling to operate multiple stream processors simultaneously, with each one working on a different shard.
Compute
Batch and stream processing have distinct requirements for compute resources.
A batch processing task requires access to a significant amount of computing power, but only for a short duration while it is executing. These jobs are typically distributed across a cluster of small compute instances, where each node processes a portion of the input data.
Once the job is completed, the compute resources can either be released for other tasks or shut down entirely, especially if the cluster is temporary.
In contrast, stream processing tasks run continuously. Therefore, they need compute resources over much longer durations. A stream processor usually has its own dedicated computing resources, which are not returned to a shared cluster. However, an exception occurs when the event volume fluctuates over time and horizontal scaling is enabled. In such instances, stream processors may need to start and stop in response to varying data volume demands for more or less computing power.
Cost
There are distinctions in the management of costs between batch processing and stream processing.
Batch processing is often more cost-efficient because it handles large volumes of data in one go. However, a batch processing task may require a greater number of compute nodes, although for a shorter duration, whereas stream processing spreads its compute usage over longer durations.
Therefore, the overall cost of a batch processing task may hinge on the efficiency with which compute resources can be returned to a shared pool and utilized for other activities. Cloud services help here by offering elastic computing, where you only pay for what you use.
Additionally, it's important to recognize that cloud providers charge extra for their managed big-data platforms used for batch processing (such as Spark on AWS's EMR). In contrast, stream processing jobs can often run on lower-cost, general-purpose compute services–especially when workloads are steady and infrastructure is right-sized.
Real Examples of Batch Processing and Stream Processing
Batch processing and stream processing each have scenarios where they represent the optimal solution in an enterprise data platform.
Batch Processing Examples
Financial statement generation: Businesses typically compile financial reports on a monthly or quarterly basis. They do this by consolidating all transactions that occur during a specific timeframe and analyzing them collectively at the conclusion of the reporting period. While real-time data may not be essential, ensuring thoroughness and precision is paramount.
Data warehouse ETL jobs: Large volumes of data from multiple sources are collected, transformed, and loaded (ETL) into a data warehouse in batches. These ETL processes run at scheduled intervals, often overnight, to minimize disruption and optimize resource usage. This method supports complex transformations and ensures data consistency, without requiring real-time updates.
Machine learning model training: Machine learning tasks often rely on batch processing to train models on extensive historical datasets, leveraging the complete data overview that batches provide. Access to substantial datasets is critical, as it greatly enhances a model’s ability to detect meaningful patterns and relationships. In contrast, stream processing methods lack access to the entire historical context of the data; they only process the most recent data, which prevents them from capturing the complete underlying patterns.
Stream Processing Examples
Real-time fraud detection in financial transactions: Streaming technology enables fraud detection systems to analyze transactions as they happen, making it possible to identify suspicious activity instantly. This rapid response is crucial, enabling financial institutions to block fraudulent behavior before any damage is done, rather than reacting after the fact.
Live social media sentiment analysis: Stream processing facilitates the real-time analysis of social media posts as they are published, allowing businesses to instantly detect shifts in sentiment and respond to new trends, crises, or opportunities. This real-time insight is crucial for protecting brand reputation, optimizing marketing efforts, and ensuring prompt customer engagement.
IoT sensor data processing for immediate alerts: IoT sensors produce vast quantities of data at a high velocity. In the case of a critical event, such as equipment failure, a business may need to respond quickly. Stream processing offers the low-latency framework necessary for real-time responses.
Hybrid Approaches
At times, a data product necessitates the quick response of stream processing along with the thorough historical analysis achievable through batch processing. In such instances, the optimal approach is to integrate both techniques.
Real-time dashboards with historical analytics: Batch processing can be used to power dashboards with comprehensive historical views of the data, uncovering complex patterns within the historical dataset. Meanwhile, stream processing can be applied to integrate the most recent events into the same dashboard, resulting in lower latency updates to the views.
AI pipeline architectures: Multiple architectural frameworks have emerged to handle large-scale data processing for AI, typically incorporating both batch ingestion and stream ingestion methods.
Implementation Tips and Best Practices
When implementing a data processing workflow, an important initial choice is whether to opt for batch processing or stream processing.
- Choose batch processing when handling large volumes of data that do not require immediate processing. Additionally, consider batch processing in cost-sensitive scenarios where scheduled processing is acceptable. Batch processing is especially advantageous for intricate analytical tasks that benefit from access to large datasets.
- Choose stream processing when your requirements include real-time data analysis, especially in scenarios where prompt decision-making is crucial, or when an application demands an immediate reaction to data alterations.
Cost and value are often central to this decision. Organizations are more likely to invest in stream processing when the business value of real-time data delivery surpasses the expenses associated with maintaining the streaming pipeline.
Another crucial decision is platform selection. In batch processing, transformations are typically performed within the data warehouse, with dbt used to manage SQL command execution. Alternatively, you might consider a vendor-neutral option like Spark, which is particularly effective when handling data stored in lakes.
In stream processing, popular tools include Apache Flink or Kafka, which provide the building blocks for scalable real-time applications. Additionally, data warehouse and platform providers are progressively offering tools for real-time processing, including Snowflake's Streams and Databricks Delta Live Tables (DLT).
When using a hosted service such as Snowflake, Databricks, or Confluent Cloud, much of the complexity is handled for you. This includes scaling the process to accommodate data volume, monitoring for latency, retrying after temporary failures, and notifying the job owner of more severe errors.
Conversely, if you run your data processing application outside of a hosted service, you might believe this approach saves costs; however, it transfers the responsibility to you to guarantee scalability and resilience in production deployments.
Regardless of whether you choose batch or stream processing, the key to cost optimization lies in effectively allocating compute resources to handle the data volume. In batch processing, you should provide enough computing power to complete tasks within a reasonable time. Similarly, stream processing requires sufficient resources to process data as quickly as it arrives. It is best to avoid over-provisioning resources, as this leads to unnecessary expenses.
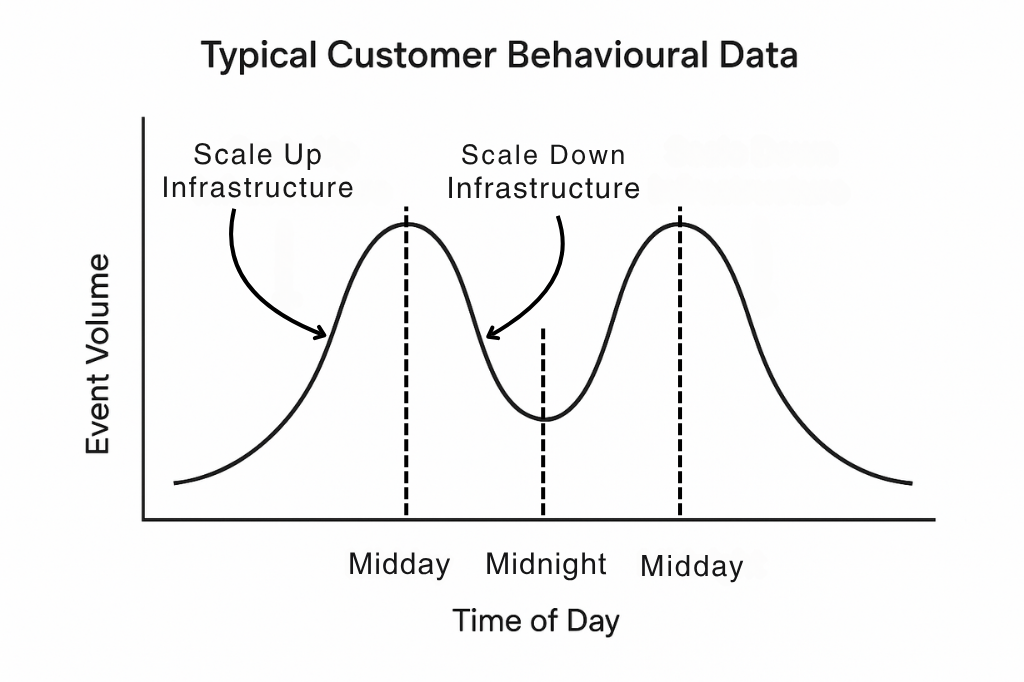
At Snowplow, the behavioral data we focus on typically exhibits a daily trend: peak data volume occurs during the day when users are active on devices, and volume drops off at night. In our stream processing applications, we use horizontal scaling of compute to match the event volume over the course of the day. For example, during the day, an application might scale out to 8 stream processors working in parallel. At night, it might scale down to just one.
Cost Optimization and Modern Solutions
Infrastructure flexibility is crucial for data teams that are creating data products. A flexible data platform is one that delivers data in formats that support both stream processing and batch processing. The data infrastructure must also equip the data team with the necessary resources throughout all phases of the development cycle.
When creating new data products, the data should be readily available in formats that are appropriate for either batch or stream processing. This enables them to prototype swiftly without incurring significant expenses. For more mature data products that already support the company's essential operations, the platform must deliver high-quality structured data, be reliable and scalable, and facilitate stream and batch processes in a manner that is cost-effective for the specific application.
The Snowplow platform is designed to offer this flexibility. It provides a reliable, low-latency stream of validated, enriched event data, enabling you to build workflows on top of a trustworthy data foundation. Snowplow supports a wide range of destinations, including Snowflake, Databricks, BigQuery, or a cloud object store. Through our streaming loaders, customers can have event data transferred into the warehouse in just seconds, allowing them to create real-time reporting.
Additionally, Snowplow facilitates real-time capabilities through event forwarding, which sends events to SaaS tools while optionally filtering or transforming the data in-stream.
For batch analysis, Snowplow customers utilize their data warehouse to carry out the resource-heavy task of processing extensive time windows of events during each execution, thereby generating views that reflect a time-aggregated perspective of customer behavior. Snowplow allows customers to schedule and execute tailored data models, adhering to a timetable that is cost-optimized for the particular model.
By supporting both stream and batch processing, Snowplow helps enterprise teams make the most of their data budgets—distributing spend across different data products and development phases. This flexibility allows teams to choose the right processing mode based on cost-efficiency and business value. And because the same trusted event source powers both paradigms, customers can scale confidently, knowing their architecture supports long-term growth and changing data volumes.
Putting It All Together: A Balanced Processing Strategy
The core differences between batch and stream processing revolve around latency, data consolidation capabilities, and the infrastructure required to support each approach. Batch processing excels at handling large volumes of historical data with complex transformations, while stream processing enables real-time insights and responsive systems. Each method comes with distinct trade-offs in cost, complexity, and data freshness.
Rather than choosing one approach exclusively, modern data teams should adopt a hybrid strategy, applying batch or stream processing based on the specific needs of the use case. Flexible data platforms—like Snowplow—make it possible to build high-quality data pipelines that support both paradigms. This empowers organizations to optimize for performance and cost today while remaining agile enough to adapt as requirements shift in the future.
Call-to-Action
If you’d like to learn how Snowplow's flexible, cost-effective platform supports both batch and stream processing paradigms, please get in touch with us. You can also book a free, no-obligation demo of the platform here.