
Identity Stitching: Snowplow vs. the Competition
The user who converts today isn’t always the same string of cookies who first landed on your site three weeks ago. Same person. But to most analytics stacks? Two different people. Maybe even three!
That’s the identity stitching problem in a nutshell. It’s been around forever, and it keeps getting harder.
When we first wrote about identity stitching back in 2014, the contest was Google Universal Analytics vs. KISSmetrics vs. Mixpanel. Of course, a lot has changed since then, but the underlying problem hasn’t.
In 2026, the competitive landscape has shifted. We have CDPs like Segment. Warehouse tools like Hightouch and RudderStack. We have teams rolling their own identity graphs in SQL. And now we have a fourth option: resolving identity in the data pipeline itself.
So let’s go through it. What identity stitching is. Why it’s hard. How the main approaches compare. And why we think pipeline-level resolution is the one that actually holds up for real-time, personalization, and agentic workloads.
What is identity stitching?
Put simply, identity stitching describes the process of connecting the events on a user’s journey, across sessions, devices, browsers, and domains, into a single record of that user.
It’s how you turn a pile of disconnected events into a unified view of customer behavior. Without it, you can’t reliably:
- Count unique users
- Run cohort analysis
- Attribute conversions
- Personalize experiences based on earlier activity
- Build agentic or predictive models that depend on customer context
It sounds simple. But it really isn’t.
Why identity stitching is hard
If you think about a typical customer journey, they rarely look the way a dashboard assumes they do. You might have a single user who visits your site on three different devices. They switch browsers mid-session, clear their cookies, share a laptop, move between sister brands, and spend weeks as an anonymous visitor before ever creating an account.
Then you have the signal-loss layer. 54% of mobile impressions lack identifiers at all, according to Comscore. Browsers like Safari and Firefox have effectively killed third-party cookies. The common identifiers we used to rely on (cookies, email addresses, phone numbers) aren’t always there when you need them.
So identity stitching, in 2026, is the process of tying whatever identifiers you do get across to one customer journey, and doing it reliably enough that everything downstream can trust it.
The three main approaches to identity stitching in 2026
Most data teams today are choosing between three architectural approaches.
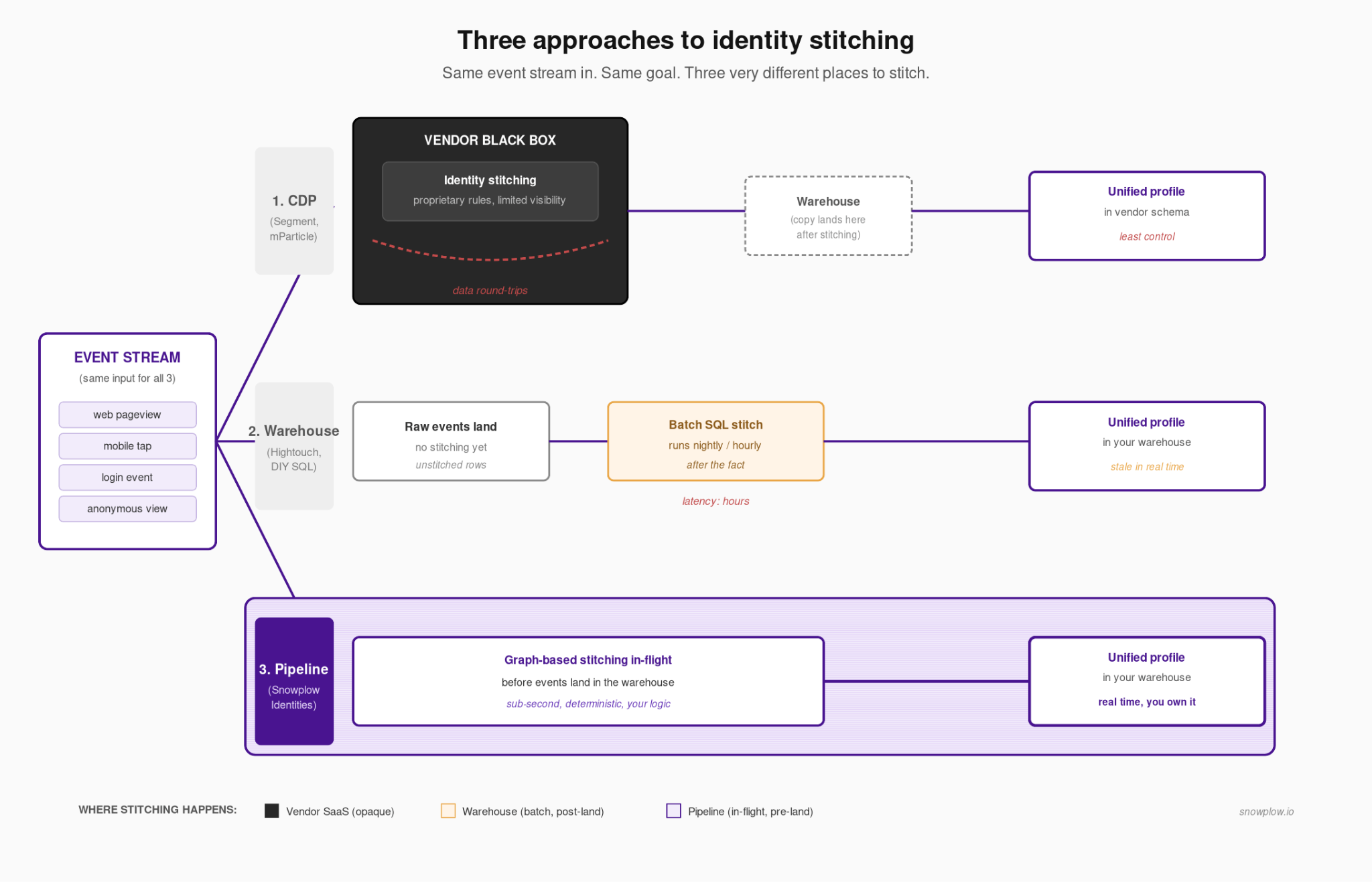
1. The CDP approach
Customer data platforms (CDPs) offer identity resolution as part of a packaged platform. You send your event data to them. They run it through their own resolution engine, build a "golden profile," and push it back out to your downstream tools.
It works, but there are catches for data teams.
First, you can't see the matching logic. The identity graph lives inside the vendor's black box. So when a merge goes wrong, you can't debug it in your own warehouse.
Most CDPs lean heavily on probabilistic, ML-based matching. That's useful for messy post-hoc data. But it's a problem when you need to explain to a compliance team, or to an agentic AI system, why two profiles got merged in the first place.
Second, these platforms were built for marketers, not application builders. The flexibility your data team actually wants — custom resolution rules, direct warehouse access to the graph — usually isn't on the menu.
2. The warehouse approach (SQL models, reverse ETL, DIY stitching)
This is where a lot of data teams have landed. You collect events, land them in your warehouse, and run graph-based stitching on top using SQL models or a reverse ETL tool.
It's clean. Your data stays in your warehouse. You own the logic.
The issue is that it relies on batch processing. You're always resolving yesterday's identity. That's fine if you're feeding reporting dashboards or delayed marketing channels like personalized email sends. But it breaks the moment you need to personalize the next page view, pass context to an AI agent mid-session, or forward a unified customer profile to an activation tool while the user is still on the site.
This approach also gets expensive. Every re-resolution is another warehouse compute job. At scale, the bill adds up fast.
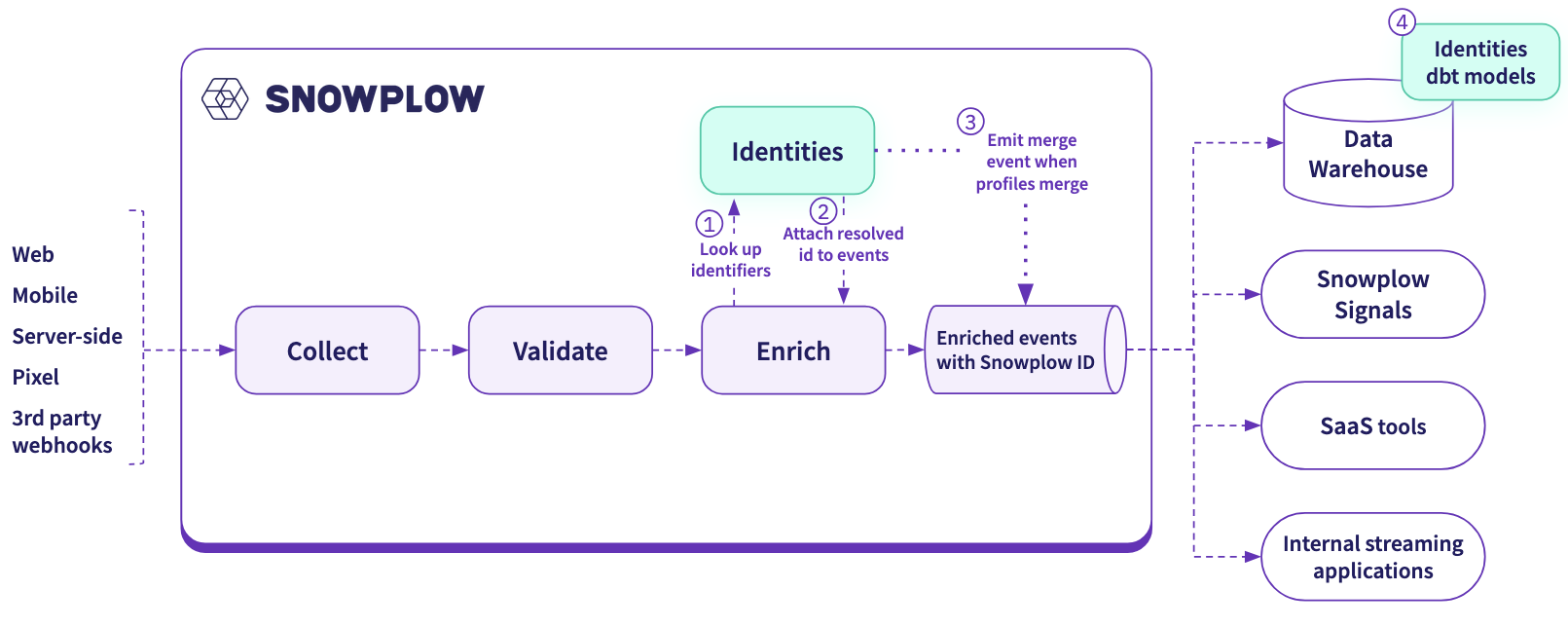
3. The pipeline approach (Snowplow Identities)
The third option, and the one we’ve been quietly building toward, is to resolve identity in the pipeline itself, before events ever hit the warehouse.
That’s what Snowplow Identities does. It’s a graph-based, fully deterministic identity resolution layer that runs on the event stream. The snowplow_id follows a user from their first anonymous interaction with your digital estate. The moment that user logs in or signs up, the anonymous snowplow_id deterministically merges with the known identifier, and the full behavioral history comes with them.
With this approach, you have two methods of sending resolved identities downstream: 1) via Snowplow Event Forwarding directly to Braze, Mixpanel, Kafka, etc or 2) via the warehouse. No probabilistic guessing, batch lag, or vendor-owned graph. Instead, you have a unified customer profile that lands in your own warehouse already resolved, and can be forwarded in flight to Snowplow Signals for ML and agentic use cases, Braze, or any downstream agent that needs identity-aware context.
Why this matters for what you’re building
Because fragmented identity is quietly wrecking your downstream use cases.
Marketers see broken journeys and duplicated profiles. Commerce Signals estimates 47% of marketing spend is wasted, largely driven by misattribution and fragmented identity.
Digital product teams can’t personalize in real time, because the “known” version of a user isn’t yet joined with their anonymous history the moment they log in.
AI agents and decisioning tools act on partial profiles. If an agent doesn’t know its user’s anonymous history, it will make inaccurate decisions with full confidence.
The last point here matters more every quarter. Gartner expects 60% of brands to use agentic AI for one-to-one interactions by 2028. But those agents can’t reason about a customer journey they can’t actually see.
The decoupling principle still holds
One thing we wrote about back in 2014 that we still stand by: data collection should be decoupled from business logic.
Your identity graph will evolve. New IDs get added (a CRM ID, a loyalty ID, an auth provider ID). Edge cases keep emerging (shared devices, cross-brand navigation, users returning after a year off). You need to change how stitching works without losing the raw event history underneath it.
Snowplow keeps the raw event stream intact, and Identities builds the graph on top. Identifier priority is configurable. Custom identifiers are supported. And output lands in your own cloud, VPC-hosted, with GDPR deletion built in. With Snowplow Identities, you run your identity graph inside your own infrastructure, with logic you can audit.
Where to go next
If you’d like to see how this works in practice, we recently shipped Snowplow Identities. You can read the product announcement here, or head straight to the Identities product page.
For a deeper look at how Snowplow compares to specific vendors, we keep up-to-date comparison pages for Segment and RudderStack.
And if you’d like to talk through your own identity stitching setup with our team, get in touch.